Leandro Doctors: Clojure CLI Tools in Debian - GSoC 2021 Partial Evaluation Report
NOTE: this blog post is based on my "Clojure CLI Tools in Debian" GSoC 2021 project Partial Evaluation Report.Hi, everybody!For those who don't know me, my name is Leandro Doctors (allentiak on IRC), and I'm the Debian Clojure Team's GSoC 2021 intern. My mentor is Louis-Philippe V ronneau[*] (pollo on IRC). My co-mentor is Utkarsh Gupta (utkarsh2102 on IRC). My 'no-mentor' :) is Elana Hashman (ehashman on IRC).In this message, I will summarize what I've been up to during the Coding I period (June 7th - July 16th).
TL;DR: my updated
[1] https://tracker.debian.org/news/1244465/accepted-data-xml-clojure-020alpha6-1-source-into-experimental/Now, let's tell the full story.During the first days of the "Coding I" phase, I did some research on thelearned the basics of packaging bumped enough to get my package accepted, I'm hopeful I can ramp up and catch up with (at least most of) my original schedule during Coding II.
TL;DR: my updated
data-xml-clojure package was accepted[1] in experimental on Wednesday night :-)[1] https://tracker.debian.org/news/1244465/accepted-data-xml-clojure-020alpha6-1-source-into-experimental/Now, let's tell the full story.During the first days of the "Coding I" phase, I did some research on the
clj dependencies. And after the precious feedback from Louis-Philippe, Elana, Utkarsh, and Alex Miller (the upstream developer of clj, among many other libraries), I came up with the following packaging strategy.- update
org.clojure:data.xml(data-xml-clojure) to 0.2.0-beta6. - package
org.clojure:tools.gitlibs(tools-gitlibs-clojure). - consider updating
libjsch-agent-proxy-java,jgit,libtools-cli-clojure(all of them already in Debian). - consider packaging
com.cognitec.aws:*packages.
- we avoid needlessly packaging
data-codec-clojure(not currently in Debian).
- we avoid needlessly packaging
- we can ignore Clojure-Script-related dependencies.
debian/).- added support for automatically tracking newer releases.
- the package now builds with Leiningen, instead of plain Java.
- it now actually supports autopkgtest (the existing test was trivial).
- Basic packaging workflow.
- Setup
sbuild[3] to make it work withgbp[4] (when I had rebuilt bidi-clojure from scratch, I had used plainsbuild.)
- Setup
- Learn how to patch upstream files with
quilt[5] (actually, via thedquiltfrontend). This was the first really difficult task to do, since it took me quite some time to grasp it. Looking back, I think I was simply scared of breaking something :)
- Learn how to patch upstream files with
- Understanding
debian/files.
- Understanding
- Understanding
debian/tests(autopkgtest) files. This was particularly difficult, since the doc wasn't clear about it. So I then improved the Clojure Packaging Tutorial[2] to make the process easier to follow.
- Understanding
data-xml-clojure package was accepted[1] in experimental on Wednesday :-)[1] https://tracker.debian.org/news/1244465/accepted-data-xml-clojure-020alpha6-1-source-into-experimental/Now that I've tools-gitlibs-clojure, you're next :-)Thank you very much Louis-Philippe, Elana, and Utkarsh (plus a special mention to Alex) for your precious support during the last few weeks!
 Despite my best efforts, I often end up with a lot of branches in my
Despite my best efforts, I often end up with a lot of branches in my  This weekend we (
This weekend we ( Before and during FOSDEM 2020, I agreed with the people (developers, supporters, managers) of the UBports Foundation to package the Unity8 Operating Environment for Debian. Since 27th Feb 2020, Unity8 has now become Lomiri.
Recent Uploads to Debian related to Lomiri (Feb - May 2021)
Over the past 4 months I attended 14 of the weekly scheduled UBports development sync sessions and worked on the following bits and pieces regarding Lomiri in Debian:
Before and during FOSDEM 2020, I agreed with the people (developers, supporters, managers) of the UBports Foundation to package the Unity8 Operating Environment for Debian. Since 27th Feb 2020, Unity8 has now become Lomiri.
Recent Uploads to Debian related to Lomiri (Feb - May 2021)
Over the past 4 months I attended 14 of the weekly scheduled UBports development sync sessions and worked on the following bits and pieces regarding Lomiri in Debian:

 Context:
Context:
 Here is my monthly update covering what I have been doing in the free software world during February 2021 (
Here is my monthly update covering what I have been doing in the free software world during February 2021 (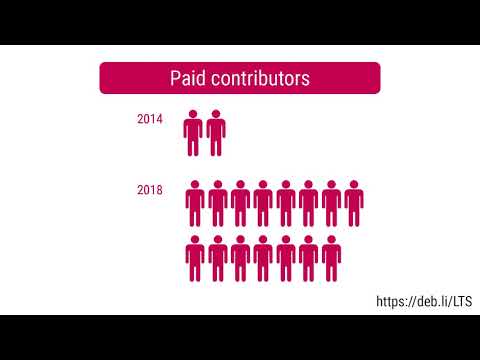
 A long journey has come to nice finish.
A long journey has come to nice finish.  The last weeks we have also worked on updating many of the KDE/Apps packages to the latest release 20.12.0, which means that as of now, Debian/unstable contains the most recent versions of KDE Frameworks, KDE Plasma, and of most KDE Apps.
Thanks goes to all the team members, in particular to (in alphabetic order) Aur lien, Patrick, Pino, Sandro, and Scarlett for their work, and to all the testers and bug reporters.
The current status is also more or less what we plan to get into Debian/Bullseye. An update to Frameworks 5.78 and Plasma 5.20.5 is still possible, but not decided by now.
Concerning my OBS packages: they are mostly superseeded by now, and all but the KDE Apps package can be removed from the apt sources. The only remaining archive of interest is
The last weeks we have also worked on updating many of the KDE/Apps packages to the latest release 20.12.0, which means that as of now, Debian/unstable contains the most recent versions of KDE Frameworks, KDE Plasma, and of most KDE Apps.
Thanks goes to all the team members, in particular to (in alphabetic order) Aur lien, Patrick, Pino, Sandro, and Scarlett for their work, and to all the testers and bug reporters.
The current status is also more or less what we plan to get into Debian/Bullseye. An update to Frameworks 5.78 and Plasma 5.20.5 is still possible, but not decided by now.
Concerning my OBS packages: they are mostly superseeded by now, and all but the KDE Apps package can be removed from the apt sources. The only remaining archive of interest is
 This creates problems because Color to Alpha works in
This creates problems because Color to Alpha works in  I'm happy to announce I handed out my Master's Thesis last Monday. I'm not
publishing the final copy just yet
I'm happy to announce I handed out my Master's Thesis last Monday. I'm not
publishing the final copy just yet This line is called a command prompt and it tells you four pieces of information:
This line is called a command prompt and it tells you four pieces of information:
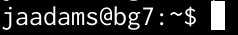 This is a shorthand notation that the shell uses to make this output shorter
when possible.
This is a shorthand notation that the shell uses to make this output shorter
when possible.  actually tells you that you are currently in the
actually tells you that you are currently in the  Welcome to the 24nd post in the relentlessly regular R ravings series, or
Welcome to the 24nd post in the relentlessly regular R ravings series, or  Some of you might have noticed that I m into keyboards since a few
years ago into mechanical keyboards to be precise.
Preface
It basically started with the
Some of you might have noticed that I m into keyboards since a few
years ago into mechanical keyboards to be precise.
Preface
It basically started with the 


